
Aprender pronúncia em inglês com música funciona, mas só quando entra na hora certa. Esse é o ponto que quase todo método ignora. Pronúncia é importante, mas não é prioridade no início do aprendizado adulto. Antes dela, existe uma hierarquia cognitiva clara que a ciência da linguagem já descreveu há décadas. Quando essa ordem é respeitada, a música vira uma ferramenta poderosa. Quando não é, ela vira ruído.
Adultos aprendem língua de forma diferente de crianças. O adulto precisa de estrutura. A gramática funciona como o eixo organizador do sistema linguístico. Sem ela, o cérebro não sabe onde encaixar o que escuta. Ellis (2003) mostrou que a aquisição implícita só se consolida quando existe algum nível de consciência estrutural. Isso significa que ouvir sons perfeitos sem entender a lógica por trás gera imitação vazia, não aprendizagem estável.
Por isso, a pronúncia não deve disputar atenção cognitiva com gramática e vocabulário no início. A memória de trabalho é limitada. Baddeley (2012) demonstrou que sobrecarregar o sistema fonológico enquanto o aluno ainda está tentando entender estrutura e significado reduz retenção geral. Em termos práticos, forçar pronúncia cedo demais atrasa o progresso.
O ponto de partida eficiente é sempre um pequeno bloco gramatical. Não para decorar regras, mas para criar previsibilidade. Quando o aluno entende como uma frase se organiza, o cérebro passa a antecipar padrões. Esse fenômeno de previsão linguística é central para a compreensão auditiva. Kutas e Federmeier (2011) explicaram que o cérebro entende linguagem antecipando estruturas, não decodificando palavra por palavra.
A partir desse bloco gramatical inicial, entra um treino forte de vocabulário. Palavras são o material que preenche a estrutura. Aqui a música já começa a ajudar, mas não pela pronúncia. Ela ajuda porque oferece contexto, repetição e carga emocional. Schumann (1997) mostrou que emoção aumenta a consolidação da memória linguística. A música cria esse vínculo afetivo de forma natural.
Nesse estágio, o foco não é como a palavra soa isoladamente, mas reconhecer a palavra quando ela aparece. É vocabulário receptivo. Nation (2001) deixou claro que vocabulário receptivo sempre precede o produtivo. O Fill the Song atua exatamente aqui ao transformar letras em desafios de reconhecimento ativo, sem exigir fala perfeita.
Depois vem a compreensão auditiva. Ouvir, ler, entender, confirmar significado e ouvir de novo. O ciclo de quatro etapas cria múltiplos caminhos neurais para o mesmo conteúdo. Vandergrift (2007) mostrou que a compreensão auditiva melhora quando o aluno alterna entre escuta global e escuta detalhada. A música favorece isso porque o aluno aceita ouvir várias vezes sem fadiga.
Nesse momento, a pronúncia ainda é leve. Ela aparece como exposição, não como cobrança. O cérebro começa a calibrar sons automaticamente. McClelland et al. (2002) explicaram que a percepção fonética se ajusta por frequência de exposição, não por correção explícita no início.
Só depois que gramática e vocabulário estão razoavelmente estáveis é que a pronúncia começa a ganhar peso. Agora faz sentido. O aluno já sabe o que quer dizer, reconhece as palavras quando ouve e entende a frase como um todo. A pronúncia deixa de ser um esforço consciente e passa a ser um refinamento.
É aqui que música vira uma aliada direta da pronúncia. Ritmo, melodia e repetição criam um molde temporal para os sons. Patel (2008) demonstrou que música e linguagem compartilham redes neurais ligadas a timing e prosódia. Ao cantar ou imitar, o aluno internaliza padrões de connected speech, redução de sons e ritmo frasal sem precisar decorar regras.
A técnica de shadowing funciona bem nesse estágio porque ela exige pouco planejamento linguístico. O aluno não precisa formular frases, apenas acompanhar. Arguelles defendeu o shadowing como ponte entre compreensão e produção justamente por isso. Com música, essa ponte fica ainda mais estável porque o ritmo guia a fala.
Trava línguas também funcionam, mas com objetivo específico. Não para fluência, e sim para resolver sons problemáticos. Flege (1995) mostrou que adultos mantêm sotaque principalmente por interferência da língua materna em fonemas específicos. Trabalhar esses pontos isoladamente evita frustração e não rouba foco do resto do sistema.
A fluência vem depois. Ela explode quando a base está sólida. Fluência não é falar bonito, é falar rápido com pouca carga cognitiva. Segalowitz (2010) mostrou que fluência surge quando processamento lexical e gramatical se torna automático. Antes disso, treinar fala livre só gera travamento.
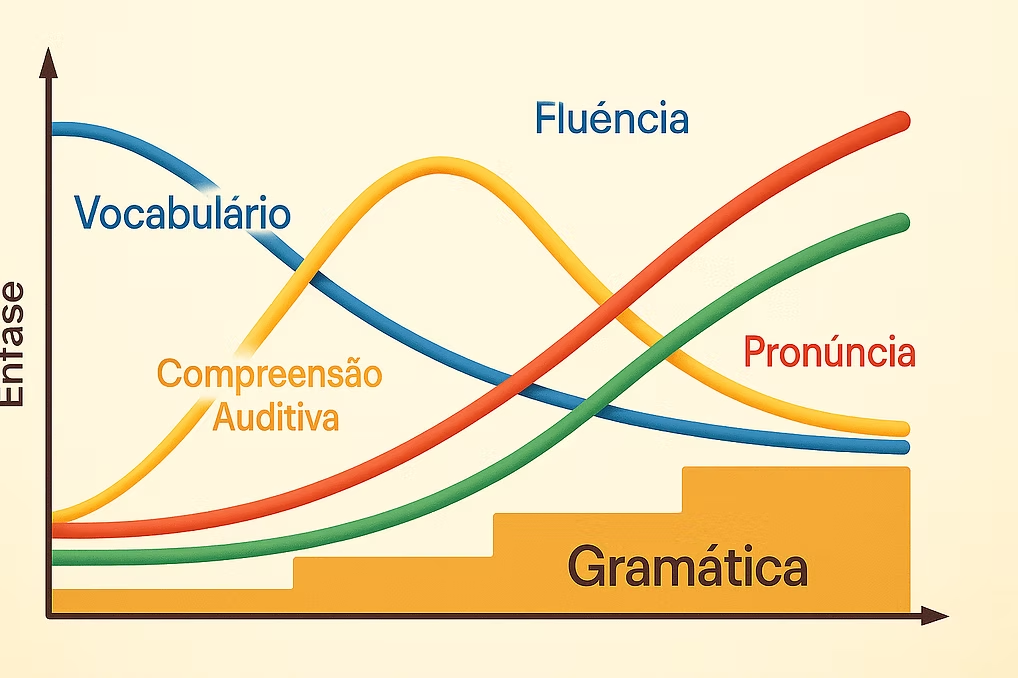
O gráfico de progresso deixa isso claro. A gramática cresce em degraus e abre novas fases. O vocabulário começa alto e depois desacelera. A compreensão auditiva sobe forte e depois estabiliza. A pronúncia cresce de forma contínua, sem picos abruptos. A fluência dispara mais tarde. Esse ciclo respeita a arquitetura cognitiva do adulto.
Quando a música é usada dentro dessa lógica, ela acelera tudo. Ela puxa vocabulário, sustenta escuta repetida, cria familiaridade com padrões sonoros e prepara o terreno para pronúncia e fluência sem pressão. Murphey (1992) já mostrava que músicas facilitam internalização de chunks linguísticos. Esses blocos prontos reduzem esforço na fala futura.
O erro comum é usar música como treino de pronúncia desde o primeiro dia. Isso gera a sensação de progresso, mas pouco avanço real. O aluno canta sem entender, imita sem controlar e trava quando precisa falar fora da música. A sensação de fluência não se transfere.
Quando a sequência é respeitada, o relato dos alunos muda. Eles passam a entender áudio mais rápido, reconhecem padrões gramaticais automaticamente, ampliam vocabulário em menos tempo e sentem a pronúncia melhorar sem esforço consciente. A fala começa a sair com mais clareza porque o sistema está organizado.
O Lingualize organiza essa sequência de forma explícita, guiando gramática, vocabulário, compreensão auditiva, pronúncia e fluência no momento certo. O Fill the Song entra como acelerador emocional e cognitivo, transformando músicas em treino inteligente exatamente onde elas funcionam melhor.
Pronúncia importa. Muito. Mas no tempo certo. Quando ela chega depois da base, a música deixa de ser distração e vira alavanca.
Referência
Ellis, R. (2003). Task based language learning and teaching. Oxford University Press.
Baddeley, A. (2012). Working memory theories, models, and controversies. Annual Review of Psychology, 63, 1–29.
Kutas, M., & Federmeier, K. D. (2011). Thirty years and counting: Finding meaning in the N400 component of the event related brain potential. Annual Review of Psychology, 62, 621–647.
Schumann, J. H. (1997). The neurobiology of affect in language. Blackwell.
Nation, I. S. P. (2001). Learning vocabulary in another language. Cambridge University Press.
Vandergrift, L. (2007). Recent developments in second and foreign language listening comprehension research. Language Teaching, 40(3), 191–210.
McClelland, J. L., Fiez, J. A., & McCandliss, B. D. (2002). Teaching the /r/–/l/ discrimination to Japanese adults: Behavioral and neural aspects. Physiology & Behavior, 77(4–5), 657–662.
Patel, A. D. (2008). Music, language, and the brain. Oxford University Press.
Arguelles, A. J. (2010). Shadowing: A powerful listening and speaking technique. In Polyglot Conference Proceedings.
Flege, J. E. (1995). Second language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech perception and linguistic experience (pp. 233–277). York Press.
Segalowitz, N. (2010). Cognitive bases of second language fluency. Routledge.
Murphey, T. (1992). Music and song. Oxford University Press.


